
PrismaとPlanetScaleで日本語に対応した検索機能を実装する
この記事では、TypeScriptベースのデータベースORM[Prisma]とMySQL互換のクラウドデータベースサービス[PlanetScale]を使って文章の検索機能を実装する方法について解説していきます。
基本的なところ
一般的に、サイト内の記事の中からある検索ワードを含む記事を抽出する機能を「全文検索」といいます。 全文検索の実装は様々ですが、今回はリレーショナルデータベースを用いた最も簡単な実装を行います。
MySQLにはFull-Text Search Functions(全文検索機能)というものが存在しているため、基本的にはこの機能を利用することになります。
PlanetScaleの対応状況
まずはPlanetScaleで全文検索機能が使えるかについてですが、公式ドキュメントはディスカッションを見た限りでは"全文検索に対応している"という説明は見当たりませんでした。 ですが、"MySQL-compatible"と謳っているので、全文検索機能は使えるものとして話をすすめます。
Prismaの対応状況
Prismaではバージョン3.8.0でMySQLでの全文検索機能がプレビューリリースされました。 PlanetScaleはMySQL互換のAPIを提供しているため、Prisma側がMySQLでの全文検索に対応していれば、PlanetScaleでも使えるはずです。
PlanetScaleもPrismaも一応全文検索には対応していそうですね。
実際に使ってみる
全文検索ができそうなところまでは確認できたので、実際に動かして試してみようと思います。
Prismaのschema定義
全文検索機能を有効にする
Prismaの全文検索機能はプレビューであるため、利用するにはpreviewFeaturesにて有効化する必要があります。
schema.prismagenerator client { provider = "prisma-client-js" previewFeatures = ["fullTextSearch", "fullTextIndex"] }
今回はfullTextSearchとfullTextIndexの2つの機能を有効にします。
検索対象モデルを作成する
今回は記事という意味のArticleというモデルを定義します。 Articleはタイトル(title)と記事の本文(content)をもつモデルです。
schema.prismamodel Article { id String @id @default(cuid()) authorId String title String content String @db.Text createdAt DateTime @default(now()) updatedAt DateTime @updatedAt @@fulltext([content]) }
@@fulltextでフルテキストインデックスを有効にします。
今回はcontentのみを検索対象にしました。
その後
$ npx prisma db push
等で変更をプッシュすれば下準備は完了です。
試してみる
これで全文検索機能は使えるようになりました。
適当なArticleレコードを作って実際に検索をしてみます。
const search = "long"; const result = await prisma.article.findMany({ where: { content: { search: search, }, }, });
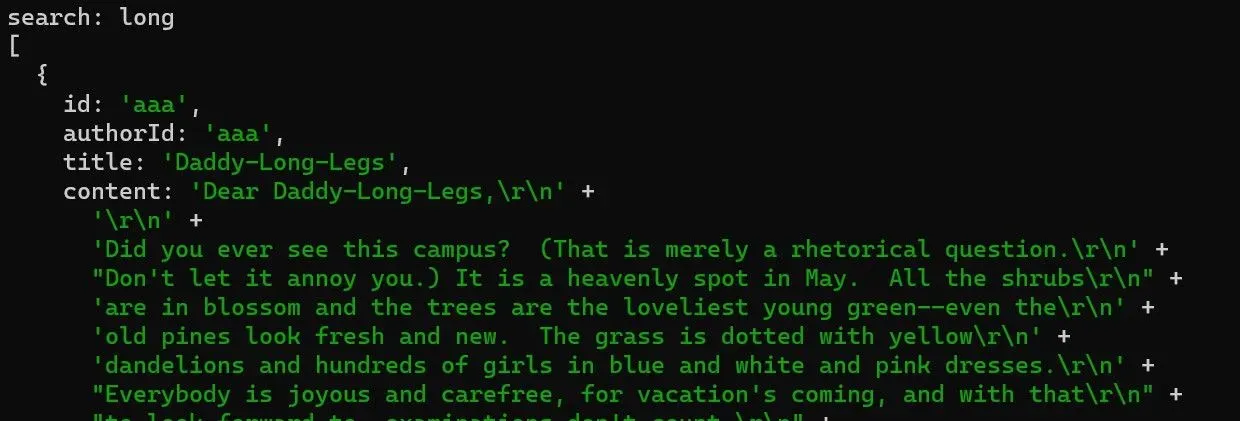
できました。良さそうですね。 しかし、日本語を検索する場合はうまく動作しません。
日本語対応をする
基本的な使い方では日本語の検索に対してうまく機能しませんでした。 これを解決していきます。
なぜ日本語だとだめなのか
MySQLの全文検索機能は、テキストをあるルールに従って短い文字列に分割し、その短い文字列をインデックスにするという機能です。
このあるルールというのは、デフォルトだと空白(スペース文字)をデリミタとして分割するというものになっており、英語の文章は単語を空白で区切っているため機能するのですが、日本語は単語を区切る明確なデリミタが存在しないため、日本語の文章をそのままDBに保存しても細かいインデックスが作られないというわけです。
n-gramフルテキストパーサー
この問題の解決策はあるルールを変えるというのが一般的です。
特によく使われるのはn-gramというものです。
ここでは詳細な説明は省略します。
下記のMySQLの公式ドキュメントを読むとなんとなくわかると思います。
MySQLでは、以下にフルテキストインデックスを作ることでフルテキストパーサーがngramになります。
CREATE FULLTEXT INDEX ft_index ON articles (content) WITH PARSER ngram;
prismaによるスキーマ定義ではまだフルテキストパーサーをngramにする術が無いため、上記のSQLを手動で実行するか、prismaのアップデートを待つ必要があります。
形態素解析による単語分割
n-gramではない単語分割の方法として、形態素解析を使うものがあります。 形態素解析というのは、ある文章を文法・辞書情報に基づいて単語に分割し、各単語の品詞などを判別する処理のことを指します。
形態素解析を行うと、単語が空白で区切られていないような文章でも単語ごとに分割することができます。
MeCabをつかう
この形態素解析を行う有名なライブラリとして"MeCab"があり、このMeCabをつかってフルテキストインデックスを生成するMeCab フルテキストパーサープラグインというものがあるのですが、これはプラグインを導入する必要があります。 PlanetScaleにはユーザーがプラグインをインストールする機能が無いため、このプラグインを使うことはできません。
但し、以下のような方法で形態素解析を使った検索機能を実装することができます。
PlanetScaleで形態素解析フルテキストインデックスを行う
まず、ある文章について、サーバー側で形態素解析を行います。 ここで使うライブラリは任意ですが、形態素解析を行うには辞書が必要で、辞書ファイルは100MBを超えます。例えばVercelのServerless Function上で動作させる場合、サイズが50MBを超えることは出来ないため、手前で用意した辞書ファイルを用いて形態素解析を行うのは現実的ではないです。 形態素解析サービスを利用するのが良いでしょう。有名なものは以下の3つあたりでしょうか。
単語が分割出来たら、すべての単語を半角スペースで結合します。
const splittedContent = "あの イーハトーヴォ の すき とお った 風 、 夏 でも 底 に 冷たさ を もつ 青い そら 、うつく しい 森で 飾ら れた モリーオ 市 、 郊外 の ぎらぎら ひかる 草 の 波 。"
形態素解析によって単語を分割された文章を保存するという方法で形態素解 ↑のような文章が出来たら、それをデータベースに保存します。 スキーマ定義は以下のように変更しておきます。
model Article { id String @id @default(cuid()) authorId String title String content String @db.Text splittedContent String @db.Text createdAt DateTime @default(now()) updatedAt DateTime @updatedAt @@fulltext([splittedContent]) }
あとはMySQLのデフォルトのフルテキストパーサーが空白で区切られた文字列ごとにインデックスを生成します。 これで形態素解析による全文検索が実装できました。
おわりに
というわけで、今回はPrismaとPlanetScaleで全文検索する方法についての記事でした。
正直なことを言ってしまうと、検索体験を突き詰めていくと「漢字・ひらがな・カタカナも柔軟に解釈できるようにしたい」 や「関連度順に並んでほしい」等、要求が増えていきngramや単純な形態素解析でのインデックス検索では対応できなくなってくるので、そういった場合はElasticSearchやAlgolia等の最適な全文検索ソリューションを採用することをオススメします。
とは言え、今回の実装はPlanetScaleがあれば動作するためとても安価に済むので、それは利点といえるでしょう。
この記事がだれかの役に立てば幸いと思います。

